
Research
Learning to Think and Act in the Physical World
Columbia Engineers are teaming up with the Toyota Research Institute to make robots smarter.
Many of the flashiest robotics demonstrations have a dirty secret: the machine cannot adapt to even slightly different circumstances. A robot that consistently makes a half-court shot from a certain spot on a basketball court would probably miss if you moved it just a few inches left or right.
“Designing a robot that generalizes its behavior to new scenarios is a huge challenge,” says Carl Vondrick, the YM Associate Professor of Computer Science at Columbia Engineering. “We are building new algorithms and hardware that make it easier for robots to extrapolate their skills, like a person would.”
Vondrick and Yunzhu Li, assistant professor of computer science at Columbia Engineering, are leading projects that aim to help robots learn from experience and adjust to changing environments on their own. With these projects, backed by the Toyota Research Institute (TRI), the researchers aim to apply recent advances in AI to machines that can sense, reason, and act safely in the physical world.
“Our university research program exists to pursue bold, boundary-pushing ideas that often extend beyond what we would normally take on internally,” said Kate Tsui, Program Director of University Research Partnerships at TRI. “These collaborations let us explore what’s possible and build strong connections with academic thinking that pushes the field forward.”
Dreaming in silicon
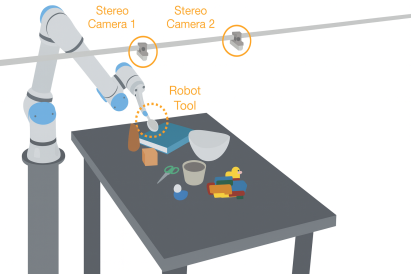
Vondrick and his students are developing a system called Dreamitate, which allows robots to envision how a person might solve a task before imitating it. The technique uses AI-generated videos, like Sora or Midjourney, to predict how the task should be accomplished.
“If the robot wants to scoop the jelly beans from one bowl to another, it imagines what it would look like for a person to do that task,” Vondrick said. “It generates a video, and then a robot imitates that example.”
This imagination-based strategy lets robots plan and adjust in situations that can’t be preprogrammed, pointing toward machines that can take on new household or industrial tasks with less retraining.
“Fundamentally, it’s about building a mental model that the robot can use to plan,” Vondrick says. People naturally build up mental models of objects in their environment, allowing them to imagine new uses for tools or apply old skills in new ways. Equipping robots with mental models has the potential to enable similar capabilities in machines.
Automatically bridging language and code

Today’s robots still struggle with natural-language commands, especially when the instructions are vague. Li’s CodeDiffuser project uses large AI models to interpret those instructions and generate task-specific code that helps the robot understand what in the scene matters for completing the task.
“We’re giving the robot both visual information about the scene and language instruction about the task,” Li said. “The system automatically generates code that acts as an intermediate step, turning those inputs into something the robot can act on.”
Using the same family of foundation models behind tools like ChatGPT or Claude, CodeDiffuser produces short Python-like snippets that describe how to locate the relevant objects or spatial relations. Running this code creates a 3D attention map—a highlighted region that guides the robot toward what it should act on.
“We call the code ‘multi-lingual’ because it can be generated by an AI model, read by humans, and executed by robots,” Li said. “It forms the link between high-level instructions and the low-level actions the robot needs to perform.”
Combining touch and vision
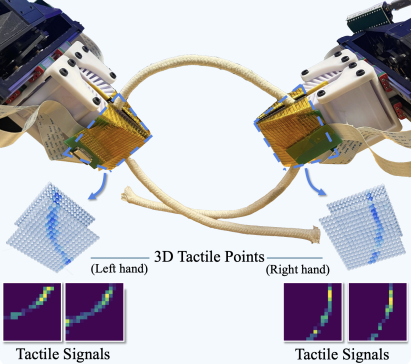
For humans, fine motor skills rely on both vision and touch. Li’s 3D-ViTac project brings those same principles to robots by combining camera images with data from high-resolution tactile sensors.
Building on Li’s graduate work at MIT on scalable tactile gloves, these low-cost, flexible sensors provide a dense grid of measurements across each robotic finger. They capture where the robot is in contact with an object and how much pressure is applied at each point, revealing detailed contact patterns that vision alone cannot see.
“We want robots to not only see what they’re touching but also feel it,” Li said. “By combining these two sources of information, they can act more safely and precisely, especially when handling delicate materials.”
To unify the two sensing modalities, Li’s team developed algorithms that fuse visual and tactile inputs into a shared 3D representation of the scene. This representation is built from both the robot’s camera and the tactile readings and can be used with imitation-learning methods called diffusion policies, allowing robots to learn complex, two-handed manipulation skills.
“High-resolution tactile sensing together with 3D vision lets robots detect slip, estimate pressure, and adjust their grip in real time,” Li said. “It improves dexterity in real environments and provides richer data for training robotic models.”
Beginning with the end in mind
Li’s team is also developing methods that help robots plan multi-step actions with stronger foresight. Their system, BaB-ND, allows a robot to explore many possible action sequences in simulation and choose the one most likely to reach a desired goal.
“It can be straightforward for a robot to predict what happens after a single action,” Li said. “It remains a hard problem to decide which actions will lead to a specific outcome.”
BaB-ND tackles this challenge by combining a learned model of physics with a systematic search strategy. The learned dynamics model predicts how objects move, collide, or deform under an action, and the search procedure divides the action space into smaller regions and eliminates options that cannot lead to good results. This lets the robot focus its computation on the most promising possibilities.
The approach enables long-horizon plans for difficult tasks such as pushing objects around obstacles, merging multiple pieces into a target configuration, threading a rope through a narrow slot, or sorting objects in clutter.
“The dynamics model provides predictions of what will happen, and the search procedure identifies which actions move the robot closer to its goal,” Li said. “This combination allows the robot to think ahead and adapt to complex situations.”
Partnering to design the future of robotics
For TRI, projects like these “help us explore what’s feasible and what’s not,” said Tsui. “They allow us to identify promising directions early and understand which ideas could eventually move from research to development and into real-world use.”
The partnership helps TRI remain aware of the vast and fast-moving frontiers of AI and robotics. For students and faculty, it offers rare insight into the challenges of building systems that must perform safely and reliably in the real world.
“It’s a partnership that keeps both sides thinking bigger about how robots can learn and adapt, and ultimately about how that research can contribute to improving people’s lives,” Tsui said.
Lead Photo Caption: Yunzhu Li’s 3D-ViTac robotics project combines camera images with data from high-resolution tactile sensors.
Lead Photo Credit: Li Lab